Get Marketing Insights First
Subscribe to receive actionable strategies, growth tips, and industry insights delivered straight to your inbox.
Claude Managed Agents handles long-running tasks and multi-step workflows so your AI operations scale without managing infrastructure yourself.
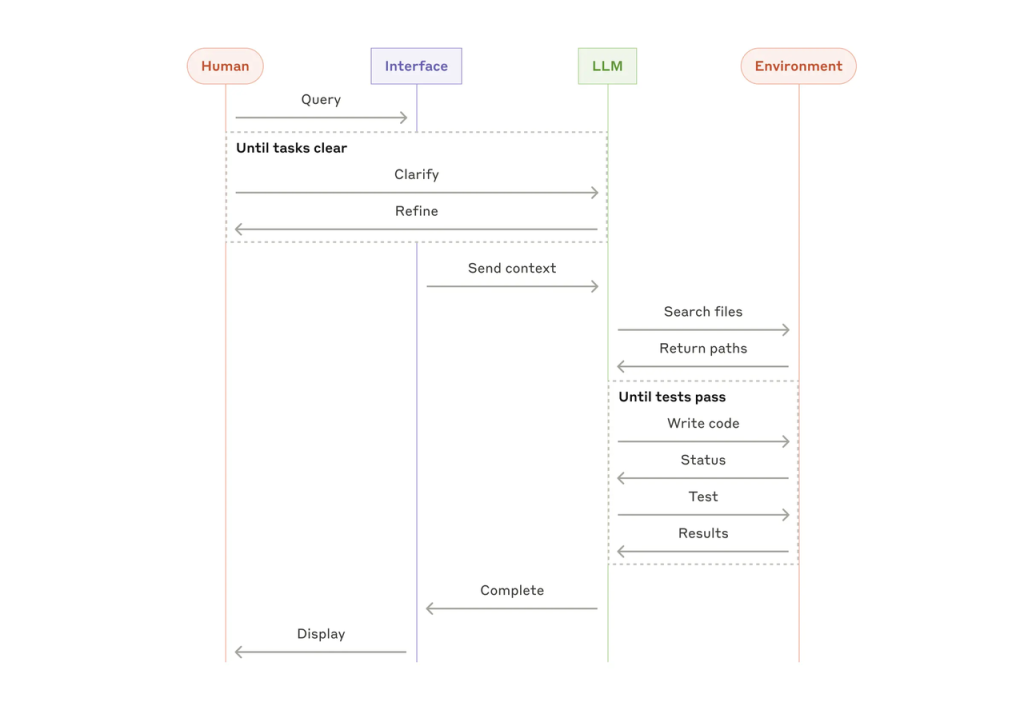
You’ve got a working agent prototype. It handles a narrow task, runs in your local environment, and mostly does what you want.
Then you try to scale it.
Suddenly you’re not building the agent anymore. You’re building the plumbing around it—session state, sandboxing, credential isolation, error recovery, context management when the task runs past your context window. Four to eight senior engineers. Three to six months. And none of that work ships any user-facing capability.
That’s the infrastructure problem that Claude Managed Agents was built to solve.
Here’s what actually happens when a team moves from “working prototype” to “production agent.”
The model part is fine. Claude does the reasoning. That was never the bottleneck. The bottleneck is everything else:
Most teams answer these questions by building their own harness. A custom agent loop. A home-rolled state store. A duct-taped error recovery system that works until it doesn’t. It’s not glamorous work, and it doesn’t scale well—because every time the model improves, the assumptions baked into your harness go stale.
Anthropic’s own engineering team documented this directly in their harness design research for long-running agents: Claude Sonnet 4.5 would wrap up tasks prematurely as it sensed its context limit approaching—a behavior they called “context anxiety.” They added context resets to the harness to compensate. Then Claude Opus 4.5 arrived, the behavior was gone, and the resets had become dead weight.
The harness was encoding assumptions about the model. The model changed. The harness didn’t.
That pattern—teams maintaining infrastructure that fights the model instead of using it—is the real problem scaling Claude agent orchestration. Managed Agents is Anthropic’s answer.
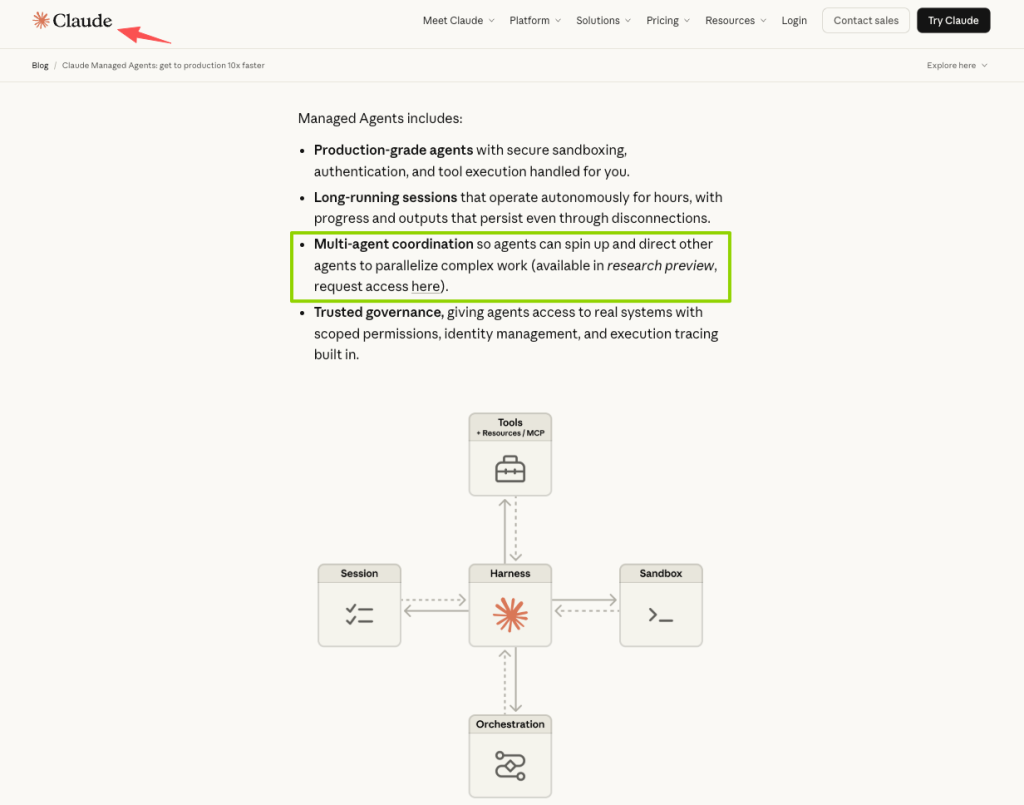
According to the Claude Managed Agents official documentation, the platform provides a fully managed environment where Claude can read files, run commands, browse the web, and execute code securely. The harness includes built-in prompt caching, compaction, and other performance optimizations for high-quality, efficient agent outputs.

The practical model has four pieces:
| Object | What it does |
| Agent | Defines model, system prompt, tools, MCP servers, and permissions. Created once, referenced by ID. |
| Environment | Cloud container with pre-installed packages (Python, Node.js, Go), network rules, and mounted files. Anthropic handles the lifecycle. |
| Session | The running unit of work. An append-only log of everything that happened. |
| Events | How the session communicates progress and takes input. Streamed via SSE. |
This is the part most teams get wrong in self-built agent systems.
When a task runs long, you face a hard choice: summarize the context and lose fidelity, trim tokens and risk dropping something important, or let the context window overflow. All three options are irreversible. Once you’ve compacted or trimmed, those tokens are gone.
Managed Agents handles this differently. The session acts as a context object that lives outside Claude’s context window. Rather than stored in a sandbox or REPL, context is durably stored in the session log. The getEvents() interface allows the brain to interrogate context by selecting positional slices of the event stream.
Concretely: the full task history is preserved. Claude doesn’t have to hold everything in its active context—it queries the session log for what it needs. You don’t lose state when the context window fills. You just work with a different slice of it.
Compaction still happens—it’s not magic. Compaction lets Claude save a summary of its context window, and the memory tool lets Claude write context to files, enabling learning across sessions. This can be paired with context trimming, which selectively removes tokens such as old tool results or thinking blocks.
The difference is what happens after compaction. In a self-managed loop, compacted messages are gone unless you built something to recover them. In Managed Agents, they’re still in the session log. The agent can query back if it needs them.
This also means context resets—used to address context anxiety in older models—become optional rather than mandatory. As models improve, you update behavior without rebuilding your infrastructure.
The brain, hands, and session are decoupled. Each can fail or be replaced independently. That architecture matters for parallel workloads.
Multi-agent coordination (one agent spawning sub-agents) is currently in research preview—worth noting if your architecture depends on it. But running multiple independent agent sessions in parallel is available now. Each session gets its own isolated container, its own credential scope, its own event log.
People use “long-running” loosely. It’s worth pinning down what it actually means in production.
A typical Claude API call is seconds. A basic agent loop might run for one to five minutes. Long-running, for the purposes of Managed Agents, means tasks that:
The Sentry example is concrete: Sentry paired their debugging agent with a Claude-powered agent that writes the patch and opens the PR, so developers go from a flagged bug to a reviewable fix in one flow. That’s not a single call. It’s a multi-step workflow—analyze error, locate codebase context, draft fix, run tests, open PR—that runs as a coherent session.
This is a decision with real trade-offs, not a default.
Use Managed Agents (remote sessions) when:
Stay with the Agent SDK or Messages API when:
Claude Managed Agents is Anthropic’s hosted runtime for long-running agent work. Use it when you want Anthropic to run the loop and session infrastructure for you. Stay on the Messages API or the Claude Agent SDK when you need tighter control over the loop or where the runtime executes.
The architectural decision that makes this work is separating what Anthropic describes in their engineering post on scaling managed agents as the “brain” from the “hands.”
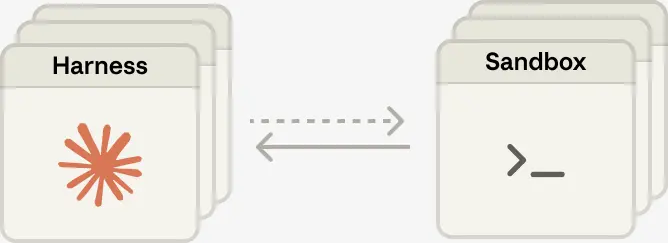
The harness leaves the container. Decoupling the brain from the hands meant the harness no longer lived inside the container. It calls the container the way it calls any other tool: execute(name, input) → string.
This sounds like an implementation detail. It’s not. It’s why the system can scale.
When brain and hands are coupled in one container, you’ve adopted what Anthropic calls a “pet”—a specific environment you have to keep alive, patch, and manage. When they’re decoupled, the sandbox becomes a disposable resource. It can crash and be replaced without taking the session with it. The session log is the source of truth, not the container.
Credentials follow the same logic. For custom tools, OAuth tokens are stored in a secure vault. Claude calls MCP tools via a dedicated proxy; this proxy fetches the corresponding credentials from the vault and makes the call to the external service. The harness is never made aware of any credentials.
The agent handles the reasoning. The infrastructure handles the secrets, the execution, and the state. That separation is what makes multi-step workflows reliable at scale.
These aren’t announced partnerships. Anthropic’s official case study page shows all three were in production before the public beta launched.
Notion integrated Claude Managed Agents to handle long-running sessions, manage memory, and deliver outputs over time. Users can now delegate open-ended, complex tasks—coding, generating slides, spreadsheets—without leaving Notion.
Asana built AI Teammates—agents embedded in project management workflows that pick up assigned tasks, draft deliverables, and hand back outputs for human review. Their CTO noted they shipped advanced features dramatically faster than prior methods allowed.
Sentry paired their existing debugging agent with a Claude-powered agent that writes the patch and opens the PR. The integration shipped in weeks instead of months on Managed Agents.
Three different architectures, three different use cases. The common thread: each team shipped in weeks, not months, because they didn’t build the infrastructure layer themselves.
This section exists because most coverage skips it. You should know what you’re getting into.
This is real, and it’s worth naming directly.
Once your agents run on Anthropic’s infrastructure with their session format and their container specifications, switching to another provider isn’t trivial. The session log format, the harness interface, the credential vault—all of it is Anthropic’s infrastructure.
If your architecture requires mixing Claude with GPT-5, Gemini, or local models in the same agent workflow, Managed Agents won’t fit. It’s Claude-specific by design.
A developer reaction circulating at launch put it plainly: “The best performance I’ve gotten is by mixing agents from different companies. Unless there is a ‘winner take all’ agent, I think the best orchestration systems are going to involve mixing agents.” If that’s where your architecture is heading, keep that trade-off in mind.
For teams evaluating whether to build their own loop instead, Anthropic’s guide to building effective agents outlines when simpler, composable patterns outperform managed runtimes.
Managed Agents billing has two dimensions: tokens and session runtime. Tokens are charged at standard Claude API model rates. The session runtime costs $0.08 per session hour.
The session-hour cost is predictable. The token accumulation is not—especially in long-running sessions with many tool calls. Compaction and prompt caching help, but batch API discounts don’t apply here. If you’ve been relying on the 50% batch discount for bulk processing, that cost structure doesn’t carry over.
For production workloads with variable task duration, budget for a range rather than a fixed number. The cost is low enough to prototype freely; at high volume, model the tool-call accumulation specifically.
Multi-agent coordination—where agents spawn sub-agents for complex tasks—is currently in research preview. Features in research preview carry meaningful instability. If your architecture depends on it, treat it as early-adopter risk for now.
Q: Can Managed Agents run tasks overnight without supervision?
Yes, that’s the designed use case. Sessions persist across the full task duration. The session log captures everything; the agent can query back into it if needed. Supervision is optional, not required. You can stream results or check the session report when the task completes.
Q: What happens if a session fails mid-task?
The session log is the durable source of truth, not the container. If the sandbox crashes, the session event history is preserved. Recovery behavior depends on how you’ve structured your agent and harness logic—the platform preserves state, but resumption behavior is something you configure. [需核实: specific automatic vs. manual resumption mechanics in the current beta]
Q: How does this compare to AWS Bedrock Agents or Vertex AI?
Different layers. Bedrock Agents and Vertex AI are model-agnostic managed services with their own agent orchestration. Managed Agents is Claude-specific infrastructure that owns more of the runtime—sandboxing, credential management, session state—but doesn’t support multi-model routing. If provider-agnostic orchestration matters to you, that’s the key distinction.
Q: Is there a way to test before committing to session-hour billing?
No dedicated Managed Agents trial exists. Standard API free credits apply. For enterprise evaluation, Anthropic’s sales team can discuss extended trial arrangements. The $0.08/hour rate is low enough that running test sessions is inexpensive—a two-hour evaluation session costs less than a cup of coffee in runtime fees, before token costs.
Q: Does scaling mean higher cost unpredictability?
Yes, with nuance. Runtime cost scales linearly with session hours—that’s predictable. Token cost scales with task complexity and tool-call frequency—that’s less predictable. The harness includes built-in compaction and prompt caching to manage token accumulation, but you’ll want to baseline your typical session token profile before projecting costs at volume.
The infrastructure problem isn’t gone—it’s just moved off your plate. That’s a real shift for teams that have been spending engineering cycles on plumbing instead of product.
If your workload involves tasks that run longer than a request-response loop, need execution environments, or currently has an engineer babysitting a fragile agent harness—that’s the gap Managed Agents closes.
Start with one workflow. Get it running reliably on the managed runtime. Then scale.